
Sa loob lang ng 3 segundo, ang isang AI na hindi pa nakarinig sa iyong magsalita ay maaaring ganap na gayahin ang iyong boses. Ito ang pinakabagong tagumpay ng artificial intelligence ng Microsoft: ang VALL-E speech synthesis model, na maaaring kopyahin ang boses ng sinuman sa kalooban sa loob lamang ng 3 segundo ng pagsasalita.
Gagayahin ng Microsoft VALL-E ang ating boses pagkatapos lamang ng 3 segundong pagsasalita
Nagmula ito sa DALL·E, ngunit dalubhasa sa larangan ng audio, at naging popular ang text-to-speech effect pagkatapos na ilabas online.
Ang ilang mga gumagamit ay nagsabi na kung ang VALL·E at ChatGPT ay pinagsama, ang resulta ay magiging hindi kapani-paniwala. Para sa iba, tila ang araw kung kailan posible na gumawa ng mga video call gamit ang AI ay hindi malayo. Mayroon ding mga nagbibiro sa pamamagitan ng pagturo na pagkatapos na makitungo ang AI sa mga manunulat at pintor, ang mga voice actor ang susunod.

Ngunit paano ginagaya ng VALL·E ang isang "hindi naririnig" na tunog sa loob ng 3 segundo?
Sinusuri ng VALL-E ang audio gamit ang mga modelo ng wika. I-synthesize ang pagsasalita batay sa "hindi naririnig" na mga tunog ng AI, ibig sabihin, zero-sample na pag-aaral.
Ang tradisyonal na text-to-speech na solusyon ay karaniwang isang pre-training mode kasama ng fine tuning. Kung ito ay ginamit sa isang zero-sample na senaryo, magreresulta ito sa hindi magandang pagkakatulad at pagiging natural ng nabuong pananalita.

Batay dito, ipinanganak ang VALL-E mula sa wala, na nagmumungkahi ng ibang ideya kumpara sa tradisyonal na modelo ng boses.
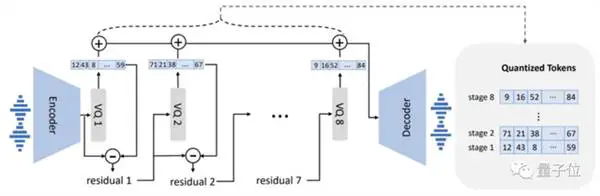
Kung ikukumpara sa tradisyonal na modelo na gumagamit ng Mel spectrum upang kunin ang mga feature, direktang isinasaalang-alang ng VALL-E ang speech synthesis bilang gawain ng modelo ng wika, ang una ay tuluy-tuloy at ang huli ay discrete.
Sa partikular, ang tradisyunal na proseso ng speech synthesis ay kadalasang ang landas ng "ponema → mel-spectrogram (mel-spectrogram) → waveform".
Ngunit binago ng VALL·-E ang prosesong ito sa "ponema → discrete audio coding → waveform":
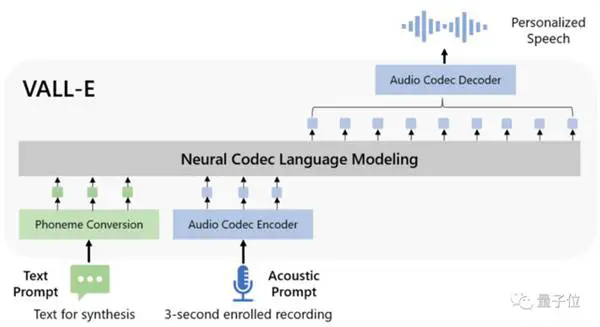
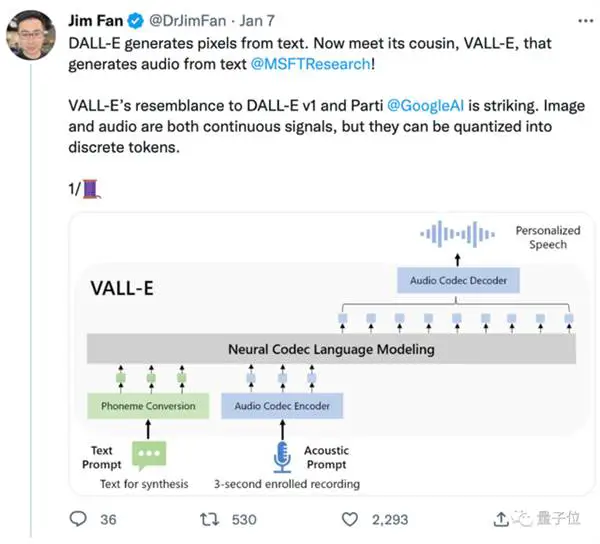
Sa mga tuntunin ng disenyo ng modelo, ang VALL-E ay katulad din ng VQVAE. Binibilang ang audio sa isang serye ng mga discrete token. Ang unang quantizer ay responsable para sa pagkuha ng audio content at mga katangian ng pagkakakilanlan ng speaker, habang ang pangalawang quantizer ay responsable para sa pagpapatalas ng signal. na parang mas natural:
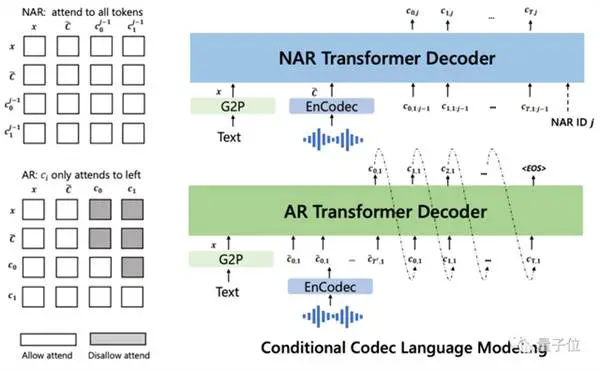
Pagkatapos ay kinokondisyon ng text at ng 3-segundong audio prompt, autoregressively itong naglalabas ng discrete audio encoding:
Ngunit hindi lang iyon, bilang karagdagan sa zero-sample na speech synthesis, sinusuportahan din ng VALL-E ang pag-edit ng boses at paglikha ng nilalaman ng boses na pinagsama sa GPT-3.
Maaari ding ibalik ang ambient background sound
Sa paghusga sa mga synthesized vocal effect, ang VALL-E ay maaaring mag-restore ng higit pa sa timbre ng speaker.
Hindi lamang ginagaya ang tono sa mismong lugar, ngunit sinusuportahan din nito ang iba't ibang bilis ng pagsasalita. Halimbawa, ito ay dalawang magkaibang mga rate ng pagsasalita na ibinigay ng VALL-E kapag ang parehong pangungusap ay binibigkas nang dalawang beses, ngunit ang pagkakatulad ng timbral ay mataas pa rin:
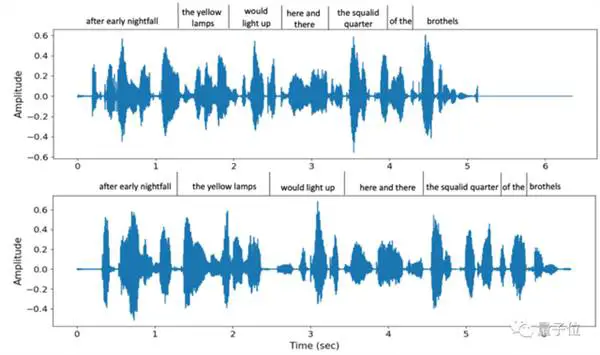
Kasabay nito, ang ambient background sound ng interlocutor ay maaari ding tumpak na maibalik.
Bukod pa rito, maaaring gayahin ng VALL-E ang iba't ibang emosyon ng nagsasalita, kabilang ang iba't ibang uri gaya ng galit, inaantok, neutral, masaya, at nasusuka.
Ito ay nagkakahalaga ng pagbanggit na ang dataset na ginamit para sa VALL·E na pagsasanay ay hindi partikular na malaki.
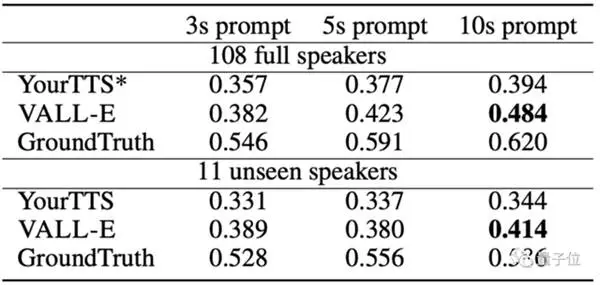
Kung ikukumpara sa Whisper ng OpenAI, na nangangailangan ng 680.000 oras ng pagsasanay sa audio at gumamit lamang ng higit sa 7.000 speaker at 60.000 oras ng pagsasanay, ang VALL-E ay nalampasan ang pre-trained na speech synthesis sa mga tuntunin ng Model YourTTS na pagkakatulad ng pagsasalita.
Bukod pa rito, narinig ng YourTTS ang mga boses ng 97 sa 108 na tagapagsalita nang maaga sa panahon ng pagsasanay, ngunit kulang pa rin sa VALL-E sa aktwal na pagsubok.
Tulad ng para sa mga patlang kung saan maaari itong mailapat:
Hindi lamang ito magagamit upang gayahin ang iyong sariling boses, halimbawa ang pagtulong sa mga taong may kapansanan na kumpletuhin ang isang pag-uusap sa iba, ngunit maaari mo ring gamitin ito upang magsalita para sa iyo kapag ayaw mo. Siyempre, maaari rin itong magamit para sa pag-record ng mga audiobook.
Gayunpaman, ang VALL-E ay hindi pa open source at maaaring kailanganin mong maghintay ng kaunti pa upang subukan ito.
Inaalok sa Amazon







